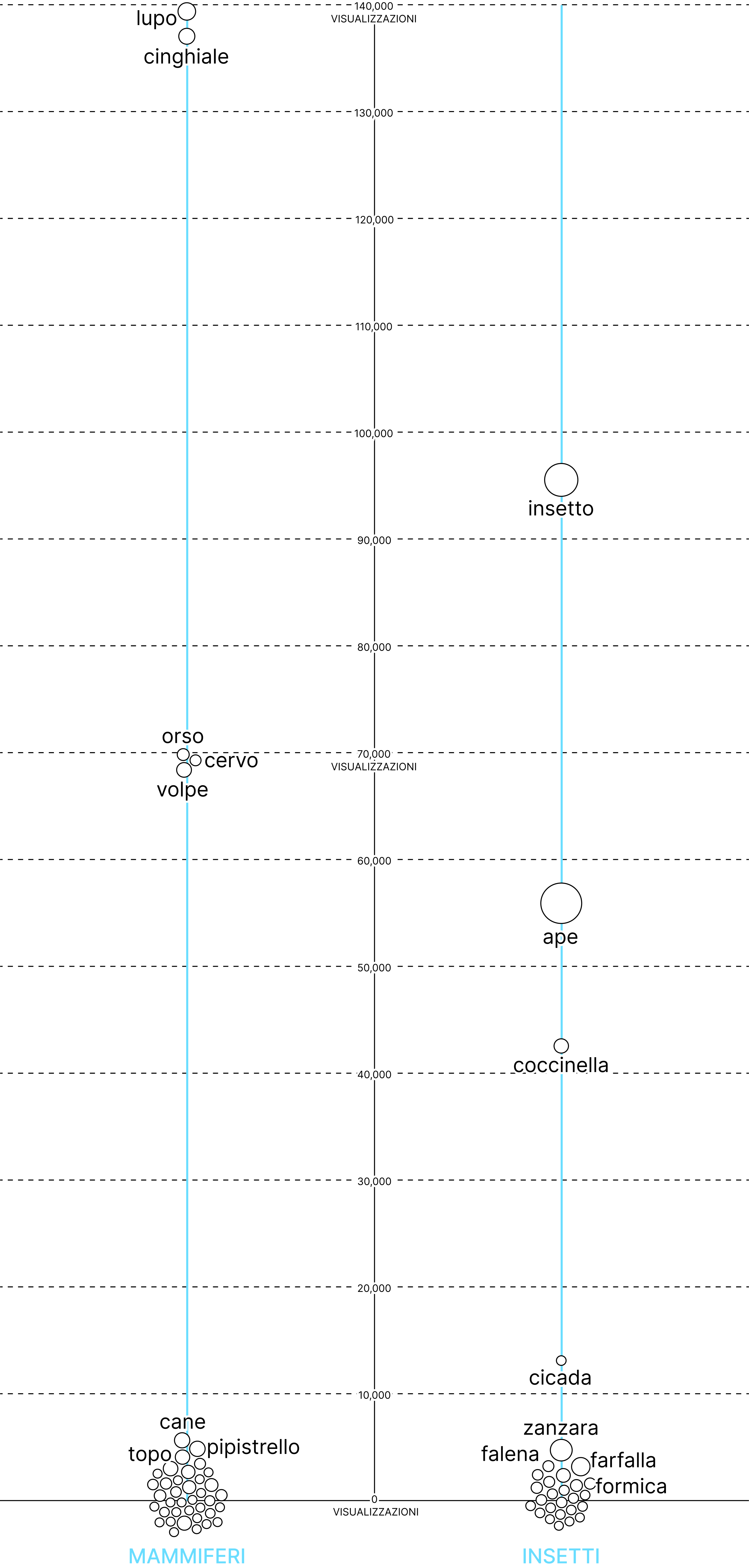
Ape, Zanzara, Piccione
Gli animali più citati nei video sulla biodiversità urbana su Youtube


















































Alessandra Facchin, Gabriele Colombo, Francesco Bonetti